Overview
A while back I made a small data service which took time series data I scraped from the web, and used it to make a data service. I used Play Framework for the API itself, and PostgreSQL as the back-end. The service wasn’t terribly complicated to put together, and I do think that building bespoke services as the need arises, rather than aiming for some sort of generic framework, can be useful. Still, there are, or must be, generic solutions that would be good enough? And maybe you already have the back-end database just sitting there and you just want to make the data available with as little effort as possible…
I did a little Googling, and came up with two pretty cool looking options. PostGraphile is a GraphQL wrapper for PostgreSQL, and has over 10k stars on GitHub!, where the claim is:
Execute one command (or mount one Node.js middleware) and get an instant high-performance GraphQL API for your PostgreSQL database!
PostgREST is a REST wrapper for PostgreSQL, and has over 17k stars on GitHub!, and claims:
PostgREST serves a fully RESTful API from any existing PostgreSQL database. It provides a cleaner, more standards-compliant, faster API than you are likely to write from scratch.
So, in this post, we’ll look at the back-end for the aforementioned time series service, and see just how easy it is to use both PostGraphile and PostgREST, and how easily they can replicate the functionality of the existing service.
Note that there are quite a few commercial options, covering frameworks such as OData, and enterprise users might prefer to go that route. That doesn’t really make this post any less meaningful, of course, since a commercial offering must be even easier, or why would anybody use it? Right? RIGHT?!
The Database Schema
The database we wish to expose is a simple set of nested tables, with schema as follows:
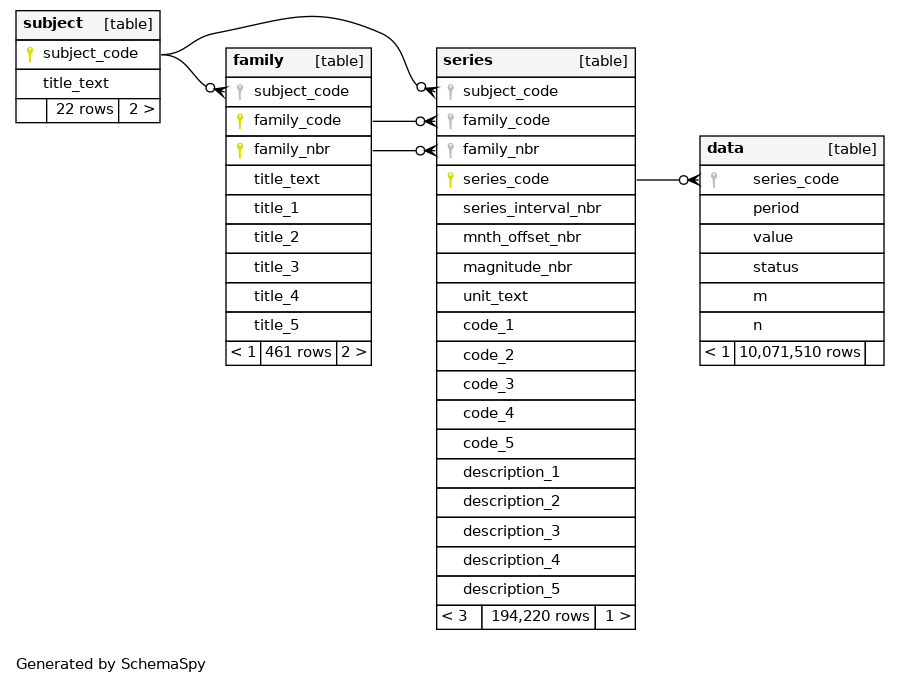
In addition, we have summarised the left-most 3 tables in a single materialized view called series_info, and with this included we have:

Our Reference Query
The reference API has a few different end-points, but let’s limit ourselves to the following request:
http://localhost:9000/snzts/v1/series?format=json&seriesCode=HLFQ.SAA1AZ&tail=4This query consistently takes around 15 milliseconds, and the payload is 1.1KB. The output looks as follows:
[
{
"subject_code": "HLF",
"subject_title": "Household Labour Force Survey - HLF",
"family_code": "SA",
"family_nbr": 7,
"family_title": "Labour Force Status by Sex by Age Group",
"series_code": "HLFQ.SAA1AZ",
"interval": 3,
"magnitude": 3,
"offset": 3,
"units": "NUMBER",
"variables": [
"Persons Employed, Unemployed, Not in Labour Force (for current quarter)",
"Sex",
"Age Group"
],
"outcomes": [
"Persons Employed in Labour Force",
"Male",
"Total All Ages"
],
"period": [
"2020.09",
"2020.12",
"2021.03",
"2021.06"
],
"value": [
1439.2,
1458.4,
1460.7,
1466.8
],
"status": [
"F",
"F",
"F",
"F"
]
}
]PostGraphile
Creating a GraphQL endpoint from our pre-existing database is comically easy–we simply run:
postgraphile \
-c "postgres://webuser:webuser@localhost:5432/snzts" \
--enhance-graphiqlWhen running, PostGraphile provides us with two endpoints, one of which is non-interactive, and one which is interactive:
http://localhost:5000/graphqlhttp://localhost:5000/graphiql
The interactive version is extremely useful, providing much assistance in crafting queries, particularly for the uninitiated:
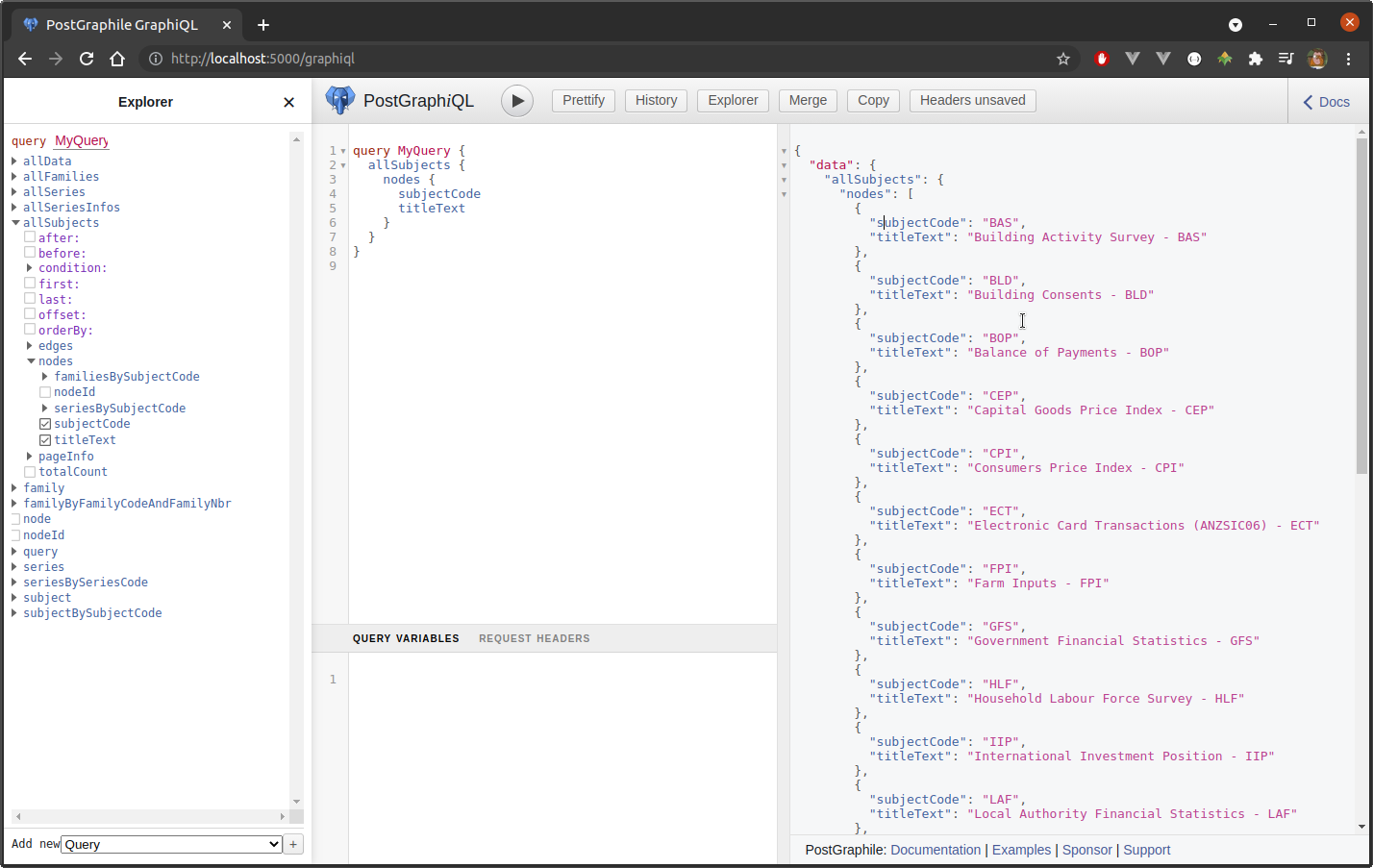
At the most basic level, each table has its own associated query which will generally be the table name prefixed with all, and converted to lower camelCase. And PostGraphile even seems to pluralise table names if they’re in the singular. For example, the subject table would be extracted via allSubjects. Individual column names are also converted to lower camelCase. For example, the column subject_code in table subject is represented as the node subjectCode. PostGraphile then relies heavily on relations within the database. For example, the subject and family tables share a foreign key relation in subject_code, and so we find embedded nodes are available as familiesBySubjectCode–again, converted to lower camelCase and pluralized.
Laid out prettily, we can get the data we want via the following GraphQL query:
{
allSubjects(condition: {subjectCode: "HLF"}) {
nodes {
subjectCode
titleText
familiesBySubjectCode(condition: {familyCode: "SA", familyNbr: 7}) {
nodes {
familyCode
familyNbr
titleText
title1
title2
title3
seriesByFamilyCodeAndFamilyNbr(condition: {seriesCode: "HLFQ.SAA1AZ"}) {
nodes {
seriesIntervalNbr
mnthOffsetNbr
magnitudeNbr
unitText
description1
description2
description3
dataBySeriesCode(orderBy: PERIOD_ASC, last: 4) {
nodes {
period
value
}
}
}
}
}
}
}
}
}To call this via cURL:
curl \
-H "Content-Type: application/json" \
-d '{"query":"{allSubjects(condition:{subjectCode:\"HLF\"}){nodes{subjectCode titleText familiesBySubjectCode(condition:{familyCode:\"SA\",familyNbr:7}){nodes {familyCode familyNbr titleText title1 title2 title3 seriesByFamilyCodeAndFamilyNbr(condition:{seriesCode:\"HLFQ.SAA1AZ\"}){nodes{seriesIntervalNbr mnthOffsetNbr magnitudeNbr unitText description1 description2 description3 dataBySeriesCode(orderBy:PERIOD_ASC,last:4){nodes{period value}}}}}}}}}"}' \
http://localhost:5000/graphql | jqThe query consistently takes around 7 milliseconds, which is very fast, and the payload is 925B. The output looks as follows:
{
"data": {
"allSubjects": {
"nodes": [
{
"subjectCode": "HLF",
"titleText": "Household Labour Force Survey - HLF",
"familiesBySubjectCode": {
"nodes": [
{
"familyCode": "SA",
"familyNbr": 7,
"titleText": "Labour Force Status by Sex by Age Group",
"title1": "Persons Employed, Unemployed, Not in Labour Force (for current quarter)",
"title2": "Sex",
"title3": "Age Group",
"seriesByFamilyCodeAndFamilyNbr": {
"nodes": [
{
"seriesIntervalNbr": 3,
"mnthOffsetNbr": 3,
"magnitudeNbr": 3,
"unitText": "NUMBER",
"description1": "Persons Employed in Labour Force",
"description2": "Male",
"description3": "Total All Ages",
"dataBySeriesCode": {
"nodes": [
{
"period": "2020.09",
"value": 1439.2
},
{
"period": "2020.12",
"value": 1458.4
},
{
"period": "2021.03",
"value": 1460.7
},
{
"period": "2021.06",
"value": 1466.8
}
]
}
}
]
}
}
]
}
}
]
}
}
}PostgREST
As for PostGraphile, getting our PostgREST endpoint up and running is pretty easy. First, we create a small configuration file, snzts.config, with the following content:
db-uri = "postgres://webuser:webuser@localhost:5432/snzts"
db-schema = "public"
db-anon-role = "webuser"We then simply run:
./postgrest snzts.configPostgREST is OpenAPI-compliant, and if we visit http://localhost:3000 we will be greeted with a complete summary of the service’s capabilities. More usefully, it is relatively easy to create documentation using swagger-ui:
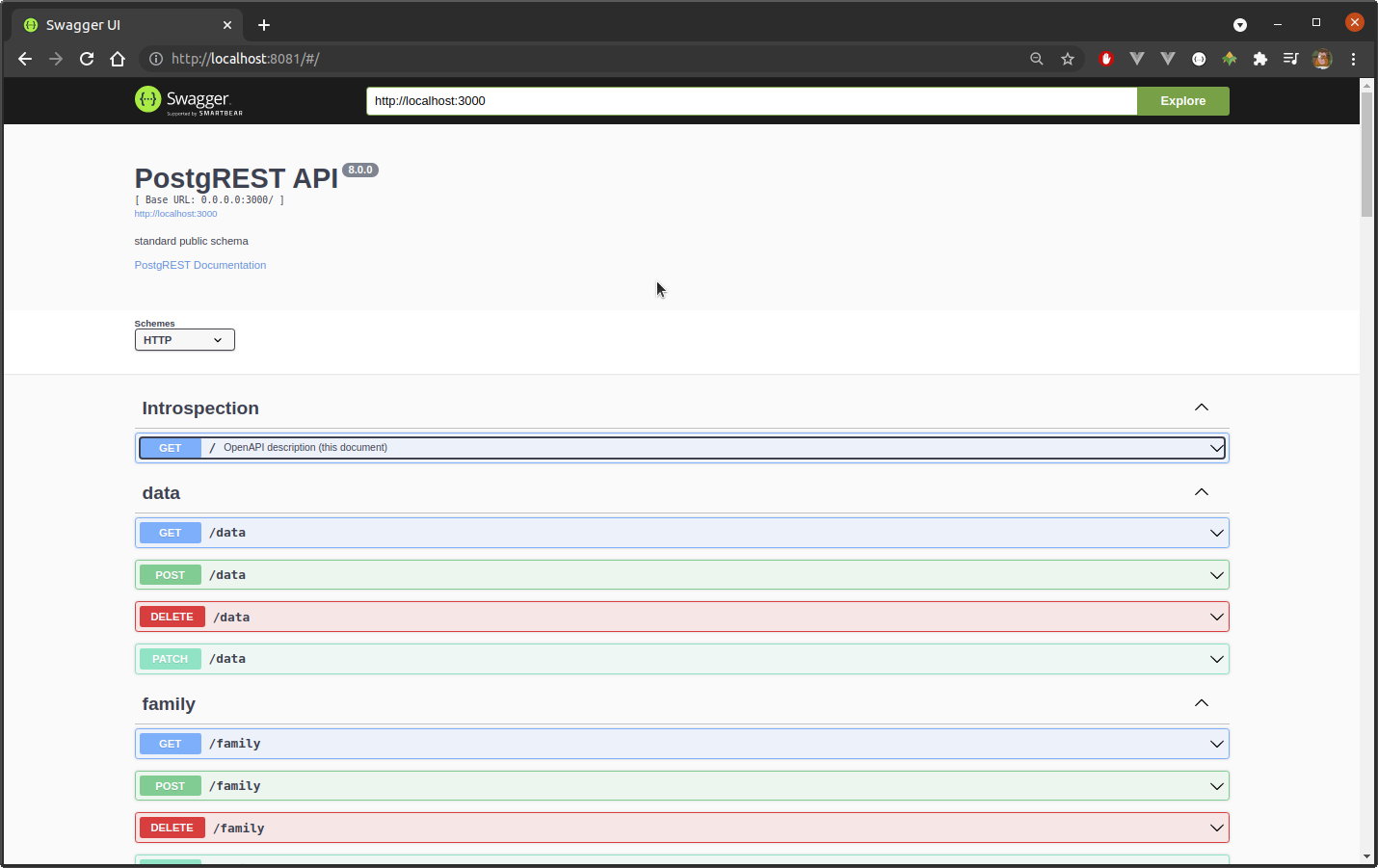
Each table appears as its own end-point, but PostgREST also allows us to perform joins based on foreign key constraints, and this applies to views and materialized views. We can emulate our reference query, then, by GETting:
curl -s \
http://localhost:3000/series_info?series_code=eq.HLFQ.SAA1AZ&data.n=lte.4&select=*,data(period,value) | jqWe’re querying the series_info table, and joining it with data, so we select series_info as our end-point, and the query parameters are as follows:
series_code=eq.HLFQ.SAA1AZdata.n=lte.4select=*,data(period,value)
The first two are obvious, filtering rows where the series_code.series_code column is equal to HLFQ.SAA1AZ, and data.n is less than or equal to 4. The last is where we specificy which columns we select, and where we join the data table (which PostgREST calls resource embedding). We select all columns from series_info by specifying *, and period and value from data by including data(period,value) in the select list. The general form is relation(<columns>), where relation is the table name or name of a foreign key constraint, and we can nest such embeddings if we need to join a number of tables.
The query consistently takes 4 milliseconds, which is ludicrously fast, and the payload is 1.07KB. The output looks as follows:
[
{
"subject_code": "HLF",
"family_code": "SA",
"family_nbr": 7,
"series_code": "HLFQ.SAA1AZ",
"subject_title": "Household Labour Force Survey - HLF",
"family_title": "Labour Force Status by Sex by Age Group",
"title_1": "Persons Employed, Unemployed, Not in Labour Force (for current quarter)",
"title_2": "Sex",
"title_3": "Age Group",
"title_4": null,
"title_5": null,
"series_interval_nbr": 3,
"mnth_offset_nbr": 3,
"magnitude_nbr": 3,
"unit_text": "NUMBER",
"code_1": "A",
"code_2": "1",
"code_3": "AZ",
"code_4": null,
"code_5": null,
"description_1": "Persons Employed in Labour Force",
"description_2": "Male",
"description_3": "Total All Ages",
"description_4": null,
"description_5": null,
"data": [
{
"period": "2020.09",
"value": 1439.2
},
{
"period": "2020.12",
"value": 1458.4
},
{
"period": "2021.03",
"value": 1460.7
},
{
"period": "2021.06",
"value": 1466.8
}
]
}
]Note that we’ve cheated a little here–rather than use PostgreSQL to figure out the last 4 rows in the selected group, we use ascending and descending ranks that were added to the data table ahead of time. PostgREST does include limit and offset functionality, but I don’t think users have access to window functions directly, for example.
Summary
In this very brief post we saw that both PostGraphile and PostgREST make it relatively easy to expose an existing database over the web, and both appear to have very good performance. PostGraphile is written with node.js, while PostgREST is a compiled Haskell program, and so the fact that PostgREST is fast in particular should not be surprising. While we really only demonstrated simple select functionality, both libraries support inserts and upserts, while PostgREST even supports remote execution of stored procedures. Which one you use would likely come down to personal preference–I’m largely unfamiliar with GraphQL, for example, and so find PostgREST somewhat more intuitive, and I also like the query parameter style.
Appendix - Installing Dependencies
PostGraphile
To use PostGraphile, one must first have Node.js installed. At the time of writing, the current LTS version of Node.js is 14.17.5, and installing is as simple as downloading and unpacking a binary archive. Something like
$ mkdir -p ${HOME}/local/node
$ curl -s \
https://nodejs.org/dist/v14.17.5/node-v14.17.5-linux-x64.tar.xz | \
tar xJvf - --strip-components=1 -C ${HOME}/local/node && \
$ echo "export PATH=\$PATH:${HOME}/local/node/bin" >> ~/.bashrcOne can then install PostGraphile by running:
npm install -g postgraphilePostgREST
Installing PostgREST simply required downloading and unpacking the following file:
https://github.com/PostgREST/postgrest/releases/download/v8.0.0/postgrest-v8.0.0-linux-x64-static.tar.xzThis contains a single binary named postgrest. Note that the program depends on the PostgreSQL API, which can be installed on Debian-like systems by running:
sudo apt-get install libpq-dev